Blueprint #5 - MLOps & Edge Deployment Architecture
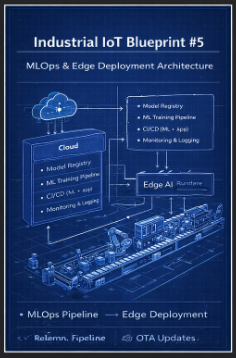
Industrial IoT Blueprint #5
MLOps & Edge Deployment Architecture
Overview
In Industrial AI systems, building a model is only the beginning.
The real challenge is:
How to reliably deploy, operate, monitor, and continuously improve AI models in real-world factory environments.
Unlike traditional IT systems, industrial environments introduce:
- Unstable network conditions
- Resource-constrained edge devices
- Strict latency requirements
- High availability constraints
This blueprint focuses on:
- End-to-End MLOps Pipeline
- Edge AI Deployment Architecture
- Model Lifecycle Management
- Continuous Feedback & Retraining
- OTA (Over-the-Air) Update Strategy
Architecture Overview
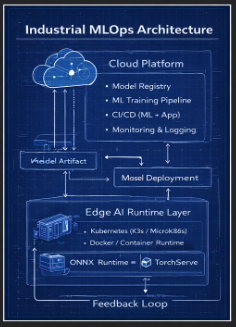
Edge Deployment Architecture
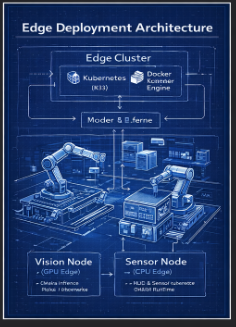
Key characteristics of edge environments:
- Low latency requirements
- Intermittent connectivity
- Hardware constraints (CPU/GPU)
Edge Stack
- Kubernetes (K3s)
- Docker Container Runtime
- Model Serving Layer:
- ONNX Runtime
- TensorRT
- TorchServe
- TensorRT
End-to-End MLOps Flow
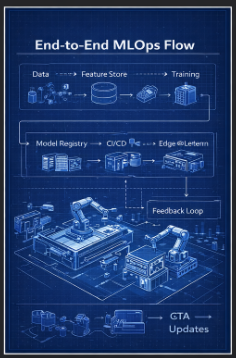
1. Data → Training
- Data is collected from Blueprint #1 Data Pipeline
- Processed and stored in Feature Store
- Model training occurs in Blueprint #3 AI Platform
Raw Data → Feature Store → Training → Model Artifact
2. Model Registry
Centralized storage for:
- Model artifacts
- Version control
- Metadata (accuracy, dataset, parameters)
Example:
| Version | Description |
|---|---|
| v1.0 | Initial deployment |
| v1.1 | Accuracy improvement |
| v2.0 | Architecture change |
3. CI/CD Pipeline (MLOps)
Git Commit ↓ Model Build ↓ Validation (Accuracy / Latency) ↓ Container Packaging ↓ Deployment to Edge
Key Capabilities:
- Automated testing
- Performance validation
- Reproducible builds
4. Edge Deployment
Models are deployed to edge environments using:
- Kubernetes (K3s / MicroK8s)
- Container-based workloads
- GPU acceleration (if available)
Deployment Patterns:
- Blue-Green Deployment
- Canary Deployment
5. Monitoring & Feedback Loop
Continuous monitoring ensures model reliability:
- Inference latency
- Data distribution shift
- Device health
This feedback is sent back to the cloud for:
- Retraining → Redeployment → Continuous improvement
Core Components
1. Model Serving
Responsible for real-time inference:
- ONNX Runtime → portability
- TensorRT → GPU optimization
- TorchServe → PyTorch deployment
2. CI/CD Pipeline
Enables automated deployment:
- GitHub Actions
- ArgoCD
3. Model Registry
Stores and manages models:
- MLflow
- S3 / MinIO
4. Monitoring & Observability
Tracks system and model performance:
- Prometheus
- Grafana
Deployment Strategies
1. Blue-Green Deployment
- Two environments (v1, v2)
- Instant traffic switch
- Safe rollback capability
2. Canary Deployment
- Gradual rollout 10% → 30% → 100%
3. OTA (Over-the-Air) Update
Remote model updates across factories Must consider:
- Network bandwidth
- Security (authentication & encryption)
- Version consistency
4. Edge vs Cloud Responsibilities
| Layer | Responsibility |
|---|---|
| Edge | Real-time inference |
| Cloud | Training, analytics |
| Hybrid | Continuous learning loop |
Key Design Principles
1. Reliability
- Must operate even when offline
- Edge autonomy is critical
2. Scalability
- Manage hundreds or thousands of edge nodes
3. Observability
- Monitor model performance in real-time
- Detect drift and anomalies
4. Security
- Model encryption
- Secure OTA updates
- Device authentication
5. Integration with Previous Blueprints
| Blueprint | Role |
|---|---|
| #1 Data Pipeline | Data collection |
| #2 Streaming | Real-time data flow |
| #3 AI Platform | Model training |
| #4 CV Architecture | Vision-based models |
Real-World Industrial Considerations
1. Network Constraints
- Edge must work without cloud dependency
- Sync occurs asynchronously
2. Hardware Diversity
- GPU Edge (Vision AI)
- CPU Edge (Sensors, lightweight inference)
3. Latency Requirements
- Sub-second inference required
- No round-trip to cloud allowed
4. Model Lifecycle Complexity
- Frequent updates
- Version compatibility issues
- Rollback requirements
Final Thoughts
**“In Industrial AI, success is not defined by model accuracy alone,but by how reliably that model operates in production.”
This blueprint represents the transition from:
- AI Development → AI Operations (AI at Scale)
Previous Blueprint
← Blueprint #4 CV Architecture